arXiv:2603.26835
ANVIL: Accelerator-Native Video Interpolation via Codec Motion Vector Priors
Shibo Liu

TL;DR
Real-time 30→60 fps video frame interpolation on mobile NPUs by reusing H.264 motion vectors instead of learned optical flow. 12.8 ms 1080p inference at 8-bit integer precision; 28.4 ms median end-to-end latency on Snapdragon 8 Gen 3.
Key Numbers
- 12.8 ms
- 1080p NPU inference, 8-bit integer
- 28.4 ms
- Median end-to-end latency, Snapdragon 8 Gen 3
- 30 → 60 fps
- Real-time frame doubling on mobile
The Problem
Real-time 1080p frame interpolation on a phone is structurally hard
Doubling 30 fps video to 60 fps on a phone gives you a hard 33.3 ms budget per synthesized frame. Modern mobile SoCs have an NPU that can hit it on paper, but the paper measures a different graph than the one frame interpolation methods actually ship. Three barriers show up the moment you try to deploy.
Operators don’t map cleanly.
Across nine surveyed VFI methods, the operators most flow-based architectures rely on
are either slow or absent on mobile NPUs. GridSample
(used by 7 of 9 methods) costs 3.2× a baseline conv on Qualcomm HTP and is
unavailable through MediaTek’s public NeuroPilot SDK. Resize 2×
costs 4.4× on HTP and 12.6× on MediaTek APU. PReLU
and LayerNorm are unmappable on MediaTek
entirely. Self-attention OOMs at 1080p on both vendors.
INT8 is the only precision that fits, and iterative flow doesn’t survive it.
FP16 inference exceeds the 33.3 ms deadline on every device tested, even RIFE at 360p.
INT8 is the practical operating point—but iterative flow methods collapse there.
IFRNet’s frame mode loses 4.38 dB PSNR under INT8; RIFE’s flow-up mode loses
0.89 dB. Per-operator instrumentation localizes the failure to a single pattern:
quantized Add on recurrent flow states (more on
this below).
The graph is memory-bound.
Profiling RIFE 360p FP16 on HTP V75, convolutions account for only 5.1% of inference
cycles. The other 95% is Resize,
GridSample, Div,
Add, Mul,
Concat, PReLU,
Slice. Mobile NPUs are tuned for compute-bound
operators; this graph is the opposite.
The Idea
The motion vectors are already in the bitstream. Use them.
The H.264/AVC decoder produces block-level motion vectors as a byproduct of normal playback. They are noisy, blocky, and not flow fields—but they are free. ANVIL takes them out of the decoder, smooths them on the GPU, and uses them to prealign the two input frames before anything reaches the NPU.
That single move dissolves the three barriers. There is no learned optical flow on the
NPU, so no GridSample and no iterative
refinement. The remaining job for the NPU is small: take the two prealigned frames
and predict a residual that fixes whatever the codec MVs got wrong. That residual
network is just convolutions and ReLUs, which mobile NPUs are good at.
The result is an inference graph that looks unlike a 2024 VFI architecture and a lot like a 2018 image-to-image network. That’s on purpose.
Architecture
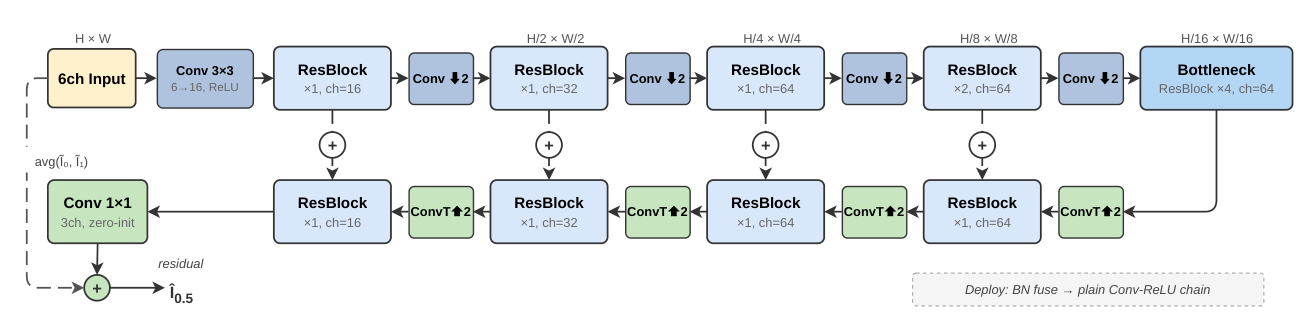
[16, 32, 64, 64] for ANVIL-S and
[16, 32, 96, 96] for ANVIL-M.
Skip connections are additive, not concat-based: this kept latency 17–26% lower
in same-session A/B tests because the NPU never has to materialize the wide concat
tensors. Batch-norm folds into the conv weights at deploy time, so the runtime graph
is plain Conv + ReLU.
System Pipeline

Results
End-to-end latency on Snapdragon 8 Gen 3
Median over 54,623 consecutive frame pairs (30-minute continuous 1080p playback, SM8650, ANVIL-S INT8). 94.9% of frame pairs complete within the 33.3 ms budget; the 5.1% that don’t are concentrated in the late thermal phase.
| Stage | Hardware | Latency | Operation |
|---|---|---|---|
| P1a | CPU | 2.9 ms | ZOH densify + 4× downsample + YUV pack |
| P1b + P2 | GPU | 3.7 ms | median-5 + Gaussian σ=2 + warp + quant |
| Copy | CPU | 0.9 ms | 12 MB uint8 NHWC to QNN buffer |
| P3 | HTP | 17.0 ms | INT8 graphExecute (async, pipelined) |
| P4 | GPU | 3.3 ms | dequant + residual + RGB→YUV420 |
| Total per pair (median) | 28.4 ms | 94.9% ≤ 33.3 ms | |
NPU forward-pass latency at 1080p INT8
Network-only inference, three Snapdragon generations. RIFE has to drop to 360p to even attempt the budget. ANVIL holds 1080p across two generations. Older HTP V69 silicon fails for everyone.
| SoC | NPU | ANVIL-S | ANVIL-M | RIFE (360p) | ≤ 33.3 ms |
|---|---|---|---|---|---|
| SD 7+ Gen 2 | HTP V69 | 46.0 ms | 56.6 ms | 45.6 ms | × |
| SD 8 Gen 2 | HTP V73 | 15.5 ms | 20.8 ms | 20.7 ms | ✓ |
| SD 8 Gen 3 | HTP V75 | 12.8 ms | 16.7 ms | 14.7 ms | ✓ |
On MediaTek (NeuroPilot Public SDK), ANVIL-S runs all operators APU-delegated at 1080p INT8: 24.4 ms on Dimensity 9300, 25.5 ms on Dimensity 9400+. The MediaTek path uses runtime compilation, so absolute timings aren’t directly comparable to Qualcomm; the point is that the operator set is portable.
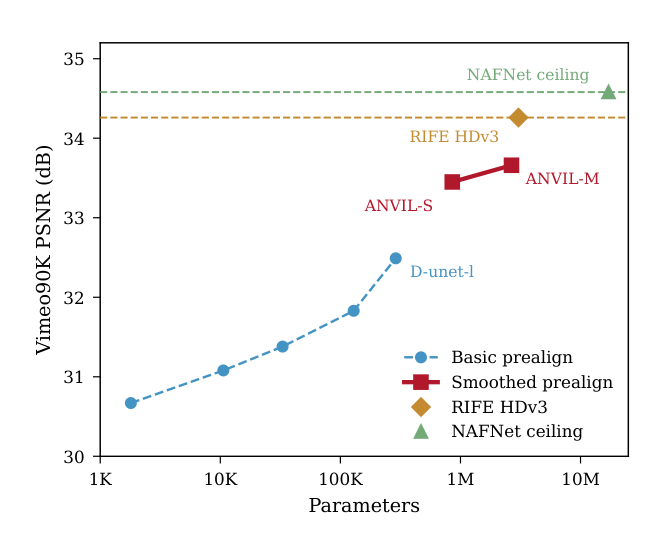
Quality vs. RIFE on Vimeo90K and Xiph 1080p
| Method | Params | Vimeo PSNR | Vimeo LPIPS | Xiph PSNR | Deployable? |
|---|---|---|---|---|---|
| MV Blend (zero-param) | 0 | 31.20 | 0.053 | 28.98 | — |
| ANVIL-S | 855K | 33.45 | 0.037 | 29.65 | Yes |
| ANVIL-M | 2.66M | 33.66 | 0.036 | 29.74 | Yes |
| RIFE HDv3 | 3.04M | 34.26 | 0.019 | 30.04 | No (grid_sample + INT8) |
| NAFNet ceiling | 17.1M | 34.58 | 0.030 | 30.30 | No (LayerNorm) |
ANVIL-M trails non-deployable RIFE by 0.6 dB PSNR on Vimeo and 0.3 dB on Xiph. LPIPS is worse (0.036 vs. 0.019), reflecting the smoothness bias of residual prediction versus sub-pixel warping. The NAFNet ceiling has the same gap, so it’s a structural property of residual VFI rather than a capacity issue.
Visual comparison

Capacity scaling
The Quantization Story
Why iterative flow methods break under INT8
INT8 post-training quantization usually loses fractions of a dB on classification and detection networks. On iterative flow VFI it loses 4 dB. Per-operator instrumentation on RIFE and IFRNet shows the failure follows the same pattern in both:
- Quantizing convolutions introduces a small initial error (CosSim drops 0.048 for RIFE, 0.055 for IFRNet). Acceptable.
- Quantizing PReLU adds zero further degradation. Benign.
-
Quantizing
Addtriggers collapse. CosSim drops to 0.815 on RIFE and 0.878 on IFRNet. This is the only operator that matters. - Full W8A8 ≈ Conv + Add. Nothing else contributes meaningfully.
The mechanism: iterative VFI accumulates flow as
faccum = faccum + Δf
across stages. Each stage’s quantized output feeds the next, and trained flow
states have a wide dynamic range (±19 px for RIFE, ±11 px for IFRNet)
that doesn’t fit cleanly in 8 bits. The error compounds.
ANVIL avoids the trap by construction. There is no recurrent flow state, so no
Add-on-recurrent-state to amplify. The
residuals it does predict have range ±0.25, comfortably within INT8. There is
no grid_sample on the NPU, so quantization
noise can’t bounce through a sampler. ANVIL-S loses 0.19 dB under INT8;
ANVIL-M loses 0.09 dB.
Components
Training and evaluation code for ANVIL-S and ANVIL-M, plus the ONNX export and INT8 calibration pipeline. Includes the per-operator quantization instrumentation used to localize the iterative-flow collapse, the cross-vendor operator benchmark (Qualcomm HTP, MediaTek APU), and the comparative evaluations against RIFE and IFRNet on Vimeo90K and Xiph 1080p.
mpv-android-anvil
github.com/NihilDigit/mpv-android-anvil →
A fork of mpv-android that runs the full three-processor pipeline live: software H.264 decode (via FFmpeg, since Android’s MediaCodec doesn’t expose per-macroblock MVs), a Vulkan compute shader for smoothing and warp, and Qualcomm QNN/HTP for INT8 inference. Includes an A/B toggle for direct visual comparison and ships with four Xiph 1080p test sequences. The teaser at the top of this page is recorded from this player.
Abstract
Real-time 30-to-60 fps video frame interpolation on mobile neural processing units (NPUs) requires each synthesized frame within 33.3 ms. We show that mainstream flow-based video frame interpolation faces three structural deployment barriers on mobile NPUs: spatial sampling operators exceed the frame budget or lack hardware support, iterative flow refinement collapses under 8-bit integer post-training quantization, and memory-bound operators dominate the inference graph. ANVIL addresses these barriers by reusing motion vectors from the H.264/AVC decoder to prealign input frames, removing learned optical flow, spatial sampling, and iterative accumulation from the accelerator graph. The remaining residual is refined by a convolution-dominated network composed almost entirely of compute-bound operators. On a Snapdragon 8 Gen 3 device, ANVIL achieves 12.8 ms 1080p inference at 8-bit integer precision; an open-source Android player sustains 28.4 ms median end-to-end latency over 30-minute continuous playback. Per-operator causal analysis identifies quantized accumulation on recurrent flow states as a key mechanism behind integer quantization failure in iterative methods. The current design targets H.264/AVC playback with decoder-exposed motion vectors.
Limitations
ANVIL is built on a specific assumption: the decoder hands you motion vectors. Today that means H.264/AVC playback with software decoding through FFmpeg. Android’s hardware MediaCodec path doesn’t expose per-macroblock MVs, so the demo player uses libavcodec on the CPU. Generalization to HEVC and AV1, and to playback paths without decoder access, is left to future work.
On the quality side, residual prediction is structurally smoother than sub-pixel warping. ANVIL’s LPIPS is roughly 2× worse than RIFE’s on Xiph 1080p (0.148 vs. 0.077). The same gap appears in the 17.1M-parameter NAFNet ceiling, so it’s a property of the paradigm, not of the model size. Perceptual-loss fine-tuning could partly close it, provided the result still survives INT8.
Thermal throttling matters. The 28.4 ms median holds in the warm steady state (minutes 6–21 of a 30-minute playback); the hot phase (minutes 22–30) has an 11% frame-drop rate vs. 2–3% in steady state. A thermal-aware frame-skip policy is a reasonable mitigation.
BibTeX
@article{liu2026anvil,
title = {ANVIL: Accelerator-Native Video Interpolation via Codec Motion Vector Priors},
author = {Liu, Shibo},
journal = {arXiv preprint arXiv:2603.26835},
year = {2026}
}